BI Discipline: Data Modelling
Concepts covered in this article: Data Model, Table, Denormalized Data
New Here? Read the Post that Started it All, and check out the Learning Map

‘Data Model’ was one of those terms that often ends up being a barrier for people who are interested in business intelligence. We get excited about organizing information and creating some standardized use of it, we go on the internet for ideas and best practices and find ourselves immediately in the weeds. The second result on a google search of ‘data model’ yielded me:
Data modeling is the act of exploring data-oriented structures. Like other modeling artifacts data models can be used for a variety of purposes, from high-level conceptual models to physical data models. From the point of view of an object-oriented developer data modeling is conceptually similar to class modeling.
Oof. You had a hunch that your blue widgets were selling better in the summer (it’s already widely known that the red ones do best in late autumn). You wanted to check your hunch, and you couldn’t figure out how to easily get that information from your records. With some historical data, you’d be better informed about which color of widget to market this summer. After some light Wikipedia reading, you ended up googling ‘data modeling’. You weren’t trying to go back to school, or at least, you were hoping to have one of the fun, approachable professors who greets you at the door and wears funny hats.
Definitions like the one above obscure the foundational simplicity of data modelling; we’re already engaging with them every day! Even though the ideas of tracking information, putting that information in a spreadsheet, and then doing calculations on that data come naturally enough, those actions aren’t thought of as creating and acting on data models. Trust me, they are.
Data models can be complex, but they don’t necessarily need to be. A list of products sold with the date of sale and information about the product is a data model. A list of donors is a data model. Heck, the grocery list languishing on your fridge is a data model. In the blue widget example above, you could check your hunch quickly if you had a list of all your widget sales, the date of the sale, and the color of the widget sold.
Data models become more complex when the questions become more complex, more time-sensitive, or we want to ask many different questions of the same data model. Each of those challenges shaped the landscape of data modelling, and the solutions to those challenges became the weeds we wade through. And we’re not going to ignore the weeds, but for the moment we’re going to step around them, gain some higher ground, and get a bigger, clearer picture. Don’t worry, we’ll come back.
Imagine for a moment a table. No, not the dinner kind. Okay, good mental exercise, but I can see how this can easily go astray. In order to be precise, I’m going to need to show you:
Table 1
| Column 1 | Column 2 | Column 3 | Column 4 | … | |
| Row 1 | |||||
| Row 2 | |||||
| … |
Tables are one way to organize information and show attributes of events. Simple, I know. But simple things are often poorly described or skipped over entirely. Let’s start to fill in the table.
Table 2
| Date | Amount | … | … | … | … |
| 01/01/19 | $35 | ||||
| 01/02/19 | $63 | ||||
| … |
Table 2 has some sample data organized in a typical way. The first row is special; it contains the headers that name each of the columns. Each row that follows is a unique record, in this case an entry for the total sales each day. Each column is a field, where the attributes of each unique record are listed.
With Table 2 we can ask questions like:
- What was our highest sales day in the past year? What was our lowest?
- What was our total sales for the Month of January this year? How does that compare with the previous January?
What if we sold more than just Widgets? Maybe we sell cool Widget Merchandise (or “Merch” if you were in a metal band in high school like I was):
Table 3
| Date | Product Category | Amount | … | … | … |
| 01/01/19 | Widget | $20 | |||
| 01/01/19 | Merch | $15 | |||
| 01/02/19 | Widget | $53 | |||
| 01/02/19 | Merch | $10 | |||
| … |
Now we’re collecting some data! We can find out what percentage of our sales are from widgets, and what percentage is driven by the fervor for widget merch that’s gripping the public. But, we still haven’t answered the question that got us into data modeling in the first place – checking the hunch about blue widgets. So, we expand our table again, getting a finer grain detail (if you’re wondering why the word grain has been bolded, good! Keep that curiosity simmering):
Table 4
| Date | Product Category | Color | Amount | … | … |
| 01/01/19 | Widget | Red | $17 | ||
| 01/01/19 | Widget | Blue | $3 | ||
| 01/01/19 | Merch | $15 | |||
| 01/02/19 | Widget | Red | $53 | ||
| 01/02/19 | Widget | Blue | |||
| 01/02/19 | Merch | $10 | |||
| … |
Sidebar: The Case of the Invisible Data
You, astute reader, might have also noticed that there are holes in our data. We’re lucky enough in this example that the row on January 2 with $0 in Blue Widget sales was recorded. It’s entirely possible that our system only records rows with nonzero sales amounts, and that can be problematic. I’ll be covering this topic in The Case of the Invisible Data. No need to worry about it now. Being the excellent tour guide that I am, I’ve created a linear path that will take you there in due time.
Now, assuming we keep good records, we can finally check the hunch that blue widgets are a summer fad. Data Modeling success! If your questions are simple, so too can be your data models. Take a moment, pause, and drink in this foundational knowledge. Now would be a good time to stand up, reach to the sky, give your body a good shake, and go share what you’ve learned. I’m serious. I’m cementing my learning by writing these articles, and you too can do the same. Tell your dog all about it, dogs are excellent listeners, and they don’t mind hearing about the basics.
Challenge 1: We start asking more questions of our data, which requires finer grain
You may have noticed something somewhat troubling in the above example. In order to ask more questions about our data, our table seems to be growing in width but also length. Over the same date range with the same total sales, we went from 2 unique records to 6. Now, imagine if widgets came in 12 exciting neon colors, and we had 5 locations where we sold widgets. You can imagine how the table will start to grow. To top that, we haven’t even added customer data to our table.
If you’re just starting out, it’s likely you’re keeping your data in a program like Excel. I’m going to out myself here. When I was in high school (in that bizarre time before widespread internet access), I once was wondering just how long a spreadsheet could get in Excel. So, being the direct learner that I am, I literally scrolled to the bottom. It takes a minute, or at least, it did the way I was scrolling. At the bottom, I saw it: 65,536 rows. We’ve come a long way, and Excel’s up to 1,048,576 now. Let’s do some quick math:
12 colors of widget plus 6 categories of merch, times 5 locations, times 365 days a year = 32,850 rows per year
Back in 2003 we would have run out of space in two years. In the modern version of Excel we’re running out of space in just under 32 years, and again, our table is still pretty simple.
It turns out, there’s a solution to the exponentially growing table problem (there are actually several, and we’ll be covering a number of them in these articles). One of the easy solutions is just use a program that can handle more rows. Power Pivot, Power BI, and SQL Databases can all handle hundreds of millions of rows. There’s also another way that we can organize our data, and that’s what I’d like to cover next.
Solution 1: One Big Table to Rule Them All
You may have noticed in the widget examples in Tables 2-4, we’re still summing up sales every day. What if, rather than designing a set of bins that daily widget sales fall into every day, we just add a row every time we sell a widget (or piece of merch) with details about the sale. Record-keeping won’t be too onerous; computers can handle this for us. On each row we list the sale along with all the relevant details.
Table 5
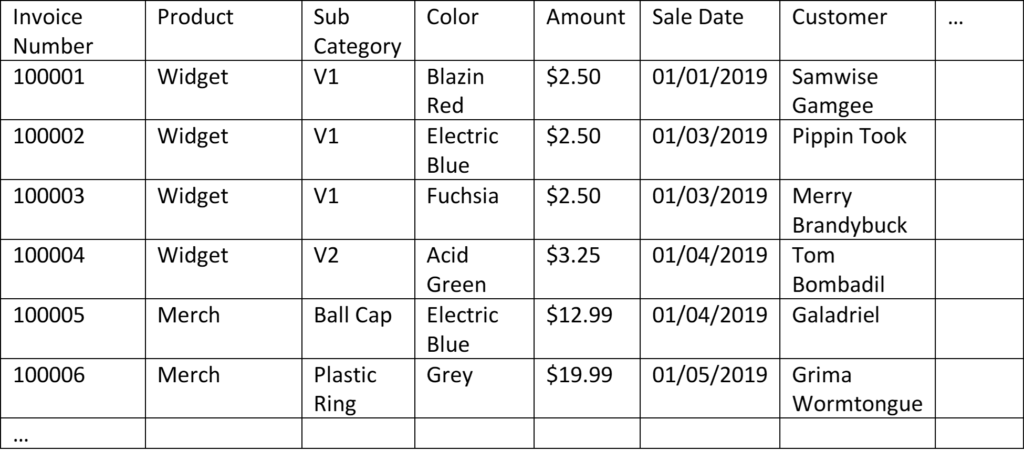
Our new table won’t balloon in size as we add details. We just add new columns for the new detail categories and begin keeping records. You can imagine adding a location column, a salesperson column, and a customer zip code column. Keep dreamin’, it’s all within your reach. For some operations, this is actually a pretty great solution. We won’t run out of space in Excel until we surpass 1 million units sold. At that point, we’re probably already upgrading to more robust and versatile data models anyway.
By the way, data organized in this way is what’s called fully denormalized. When a human (or a computer) is asking questions of the data, there’s only one table to look at. This can be easy for both the human and the computer (unless the table has too many columns, something we’ll cover in the next article). Denormalization has its drawbacks, which is why the process of normalization was invented. We’ll cover that in the next article.
In a broad sense, we now know what a data model is. We can speak to some of the challenges encountered as we begin asking more complicated questions of our models, as well as some of the solutions that address them. Time to go take a stretch break! Stand up, run around, go share what you’ve learned!
Sign up to receive email notifications when we release new learning content
Sources
I want to draw the reader’s attention to the resources available at SQLBI. All my foundational knowledge (and the foundational knowledge of the other people I’ve learned from) comes from Marco, Alberto, and Daniele. They are BI educators par excellence, and I cannot recommend them highly enough.
- Data Modeling for Power BI – Online Course from https://www.sqlbi.com/
- Medium article on Normalized vs Denormalized Data: https://medium.com/@katedoesdev/normalized-vs-denormalized-databases-210e1d67927d
Leave a Reply